Thanks to comments from Daniel Björkegren, Andreas Haupt, Philip Trammel, Brent Cohn, Nick Otis, Andrey Fradkin, Jon de Quidt, Joel Becker.
- This is a long collection of notes about economics & AI, prompted by two excellent workshops I attended in mid-September: the Windfall Trust’s “Economic Scenarios for Transformative AI” and the NBER’s “Workshop on the Economics of Transformative AI”. I had just left OpenAI’s Economic Research team, after releasing our paper, How People Use ChatGPT.
-
I’ll also try to explain a little why I’m excited about joining METR (I’ll explain why I left OpenAI another time).
- Observations.
-
- There is no standard definition of machine intelligence. There have been many attempts to give a definition or a metric of machine intelligence but most have been unsatisfactory. The lack of a common language makes work in this field difficult, but it’s also a big opportunity.
- There is no standard model of AI’s economic impact. Economists have been using a wide range of assumptions to model AI’s impact, there is no standard framework. There seems to me an opportunity for ambitious economists to propose deep models of AI’s impact. A promising line would concentrate on AI’s ability to find low-dimensional representations of the world.
- GDP will be a poor proxy for AI’s impact. AI’s benefits are likely to elude GDP for two reasons: (1) it will reduce the necessity for exchange (and GDP measures exchange); (2) it will lower the labor required for services, and the value-added from services are typically imputed from the wage-bill.
- Transformative AI will raise the relative value of resources, and possibly lower the value of labor. If computers can do all human work then there will still be scarcity in natural resources (land, energy, minerals). Because humans require resources to do work (energy, land), demand for human labor will fall, creating a gap between land-rich and land-poor.
- AI will likely have a discontinuous impact on science and technology. Many existing models treat computers as substitutes for humans in the R&D process, but there is reason to expect AI to have a qualitatively different effect on scientific progress.
-
A common thread is this that I feel economics is slightly under-fulfilling its potential. I feel there are a thousand important ways in which AI will change society, but not many attempts at grand unifying theories.
The Workshops
- The Windfall Trust workshop.
-
This workshop asked participants to discuss four possible future scenarios. Each scenario had a page-long description of what might happen, but they can be summarized as follows:
- Low capability growth (“the incremental path”)
- High capability growth without regulation (“the runaway economy”).
- High capability growth with labor-market regulation to protect jobs (“the great pushback”)
- High capability growth with redistribution (“the post-work society”)

- The NBER workshop.
- The NBER workshop was a set of chapters written for a volume on the impact of Transformative AI on a dozen different areas: R&D, media, labor, competition, etc. Attendees were presenting the chapters they had written. The workshop was organized by Ajay Agrawal, Anton Korinek, and Erik Brynjolfsson.

General Observations
- My view: we are driving in fog.
-
My personal view is that it’s reasonable to have high uncertainty about both AI progress and the effects of that progress: (1) it’s possible that AI will get very good very soon; (2) it’s difficult to anticipate what will happen if it does.
We are driving in fog: it’s possible we have miles of open road, it’s possible we’re about to hit a tree. It seems sensible to be prepared for either outcome.
- Background: a tension between AI researchers and economists.
-
Here is a very simplified characterization of AI researchers’ beliefs about economic impacts:
- AI will soon be able to replicate most human labor.
- This will cause mass unemployment.
- We should fund a universal benefit from AI company profits.
Academic economists have often bristled at these arguments:
- Economists have often been skeptics about AI capabilities and future AI progress (see below).
- Economists argue (i) there are many frictions which prevent rapid changes; (ii) even if computers were better at everything than humans, there’s still comparative advantage; (iii) new technology will create new tasks for humans.
- It’s not clear that AI companies will earn very high profits – most of the surplus from AI may go directly to the consumers of AI products.
Having spent a lot of time with both AI researchers and economists, I feel both have substantial blindspots, & could learn a lot from each other. AI people underestimate the frictions and sluggishness of economic processes; economists often fail to appreciate the speed of AI improvement & avoid having hypothetical discussions about future trajectories.
- Many economists avoided talking about transformative AI.
-
Both workshops were intended explicitly for discussion of a hypothetical: what would happen if AI capabilities approached human-level performance on most work?
Despite this, it seems to me that most of the economists resisted the hypothetical. Looking at the NBER papers I think about half were effectively discussing the effects of AI with existing capabilities, not the effects of transformative AI.
This resistance was a common topic of discussion. People gave a few different reasons for concentrating on contemporary AI instead of future AI: (1) they were doubtful that AI would improve very quickly; (2) they thought it’s more important to work on the economics of actually existing AI; (3) they thought the economics of superhuman AI was formally less interesting; (4) they thought superhuman AI was possible and important, but were nervous about being perceived as credulous by their colleagues.
Chad Jones presented a paper which took seriously the existential dangers of AI, and argued that we should be spending hundreds of billions to prevent it. After his presentation the audience gave various comments but nobody (as I recall) gave a serious counter-argument. Nobody tried to dispute the substance of the argument – that an enormous asteroid is on a path to swipe our planet. Some people said this type of preventative work wouldn’t be politically feasible – but nobody seemed to express a sense of urgency you would expect if it was only political feasibility that was holding us back. The conference discussion mostly just drifted on to the next topic.
- Defining AI capabilities is a hard problem.
-
It would be very useful to have a standard terminology for levels of AI capabilities. It would allow us to split our arguments into two parts: (1) when will AGI arrive? (2) what will happen when it gets here? We suffer from not being able to make this distinction. It is very often difficult to tell how much our disagreements are due to disagreement about capabilities progress, vs disagreement about the impact of that progress.
Conceptually the solution is simple but practically it’s hard. Many people have tried to define a set of capability levels but none have been widely adopted: most capability definitions are either too ambiguous or too narrow.1
I think this is just a fundamentally difficult problem. It feels like something you should be able to figure out in an afternoon (and I spent many afternoons on it), but it has resisted many great minds.
Here are some examples of definitions that are too ambiguous: (1) it can pass a Turing test; (2) it can do “most economically valuable labor”; (3) it can exhibit PhD-level intelligence; (4) it can do the job of a customer service worker. Each of these covers a very broad a range of interpretations, including some such that 2024-level models could already do this.
Here are some examples of definitions that are too precise: (1) it can solve ARC-AGI, (2) it can write a paper that passes peer review at NeurIPS, (3) it can earn $1M. These are relatively unambiguous but it’s also easy to imagine cases where a model passes these tests while it still has limited economic value.
- We are making some progress in characterizing AI ability.
-
In 2023 and 2024 AI ability was often described in terms of its grades on standardized tests (SAT, GRE, LSAT), or by the human-equivalent years of education, e.g. Leopold Aschenbrenner and OpenAI talked about “college-level intelligence” and “PhD-level intelligence.” This was a reasonable way of trying to make comparisons but clearly had limits: LLMs were PhD-level at some tasks, but also they were clearly kindergarten level at others.
In 2025 METR (Kwa et al. (2025)) made a good argument that a more robust metric of AI ability is the human-time-length of tasks that a model can do (see image). It’s an imperfect metric but I think it’s the best we have now.
It seems to me that having a better characterization of AI abilities, and the difference between AI and human abilities, remains a huge open question, and almost all questions about the impact of AI depend on this. This is what I’m personally most interested in working on, and the reason why I’m joining METR.
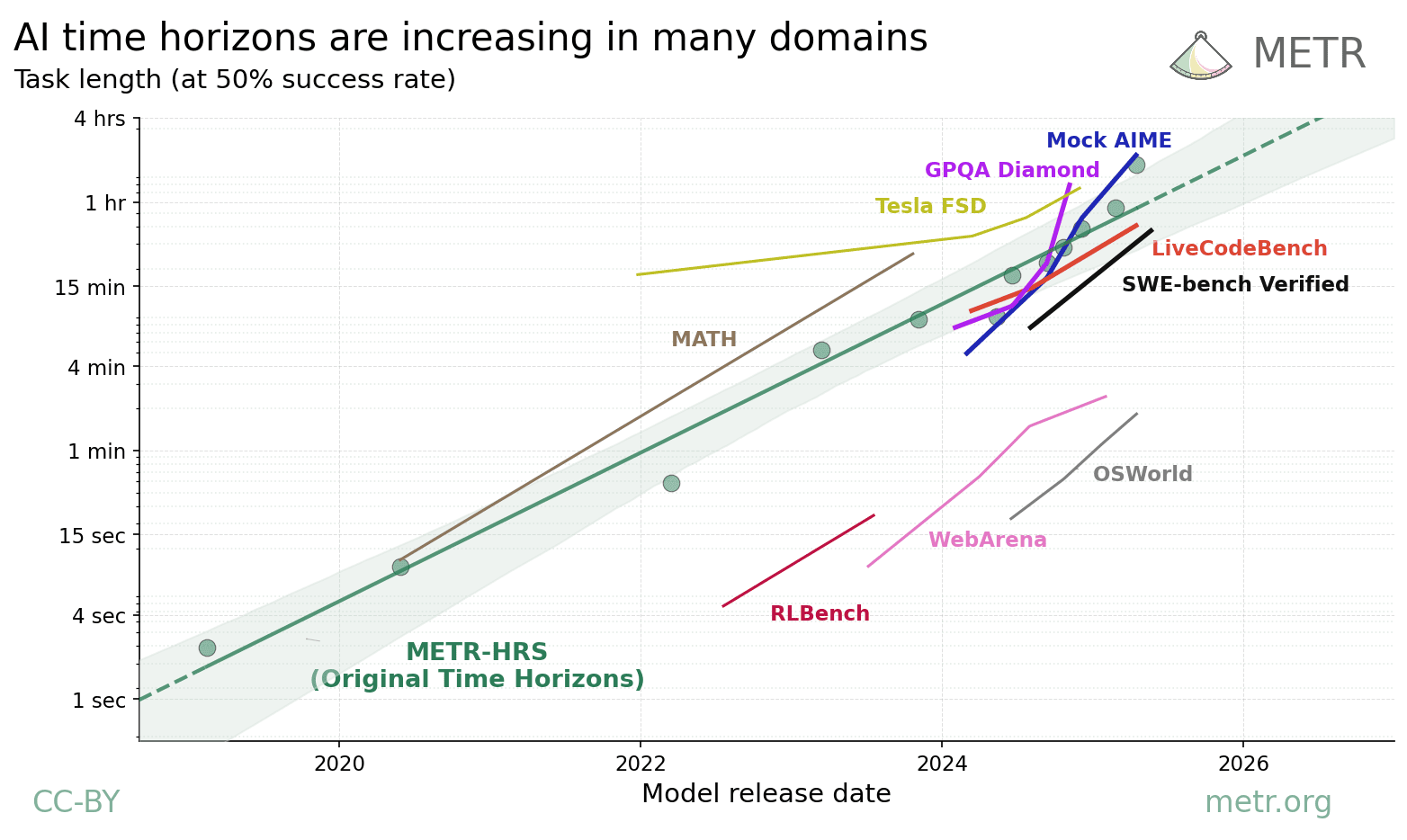 A graph of model capabilities across domains, indexed by the human-time-length of tasks, from METR.
A graph of model capabilities across domains, indexed by the human-time-length of tasks, from METR.
- I don’t think people appreciate the speed of AI improvement.
-
Speakers at the NBER workshop gave various examples of things the models still couldn’t do: (1) solve ARC-AGI puzzles; (2) extrapolate world models; (3) operate vending machines. These are all reasonable examples of limitations as of September 2025, but we should at the same time mention the rate of change. It seems very likely that the primary examples of tasks that AI cannot do in 2025 will turn into tasks that AI can do in 2026 (the same was true in 2024 and 2023).
Some general observations about the rate of progress:
- ARC-AGI is falling quickly. LLM scores on ARC-AGI-1 went from around 10% to 80% over a year, and scores on ARC-AGI-2 went from around 3% to 30% over a few months. It’s true that a large part of the performance improvement was due to adding wrappers around LLMs, but the models can write their own wrappers, so it seems likely they’ll be able to solve the class of problems which can be addressed by an LLM plus wrapper.
- Benchmarks are falling rapidly. It typically takes around 18 months for a newly introduced benchmark performance to go from 25% to 75%. We are frantically making up new tests to map out the limits of machine intelligence.
- Consumer utility is growing dramatically. Use of chatbots has been more than doubling each year, both on the intensive and extensive margins. People far prefer answers from newer chatbots to older chatbots. The Elo score of models on chatbot arena is growing at around 150 points/year. This implies about a 70% win-rate, and equivalent to the difference in skill between the top-rated chess player in the world and the player ranked 100.2
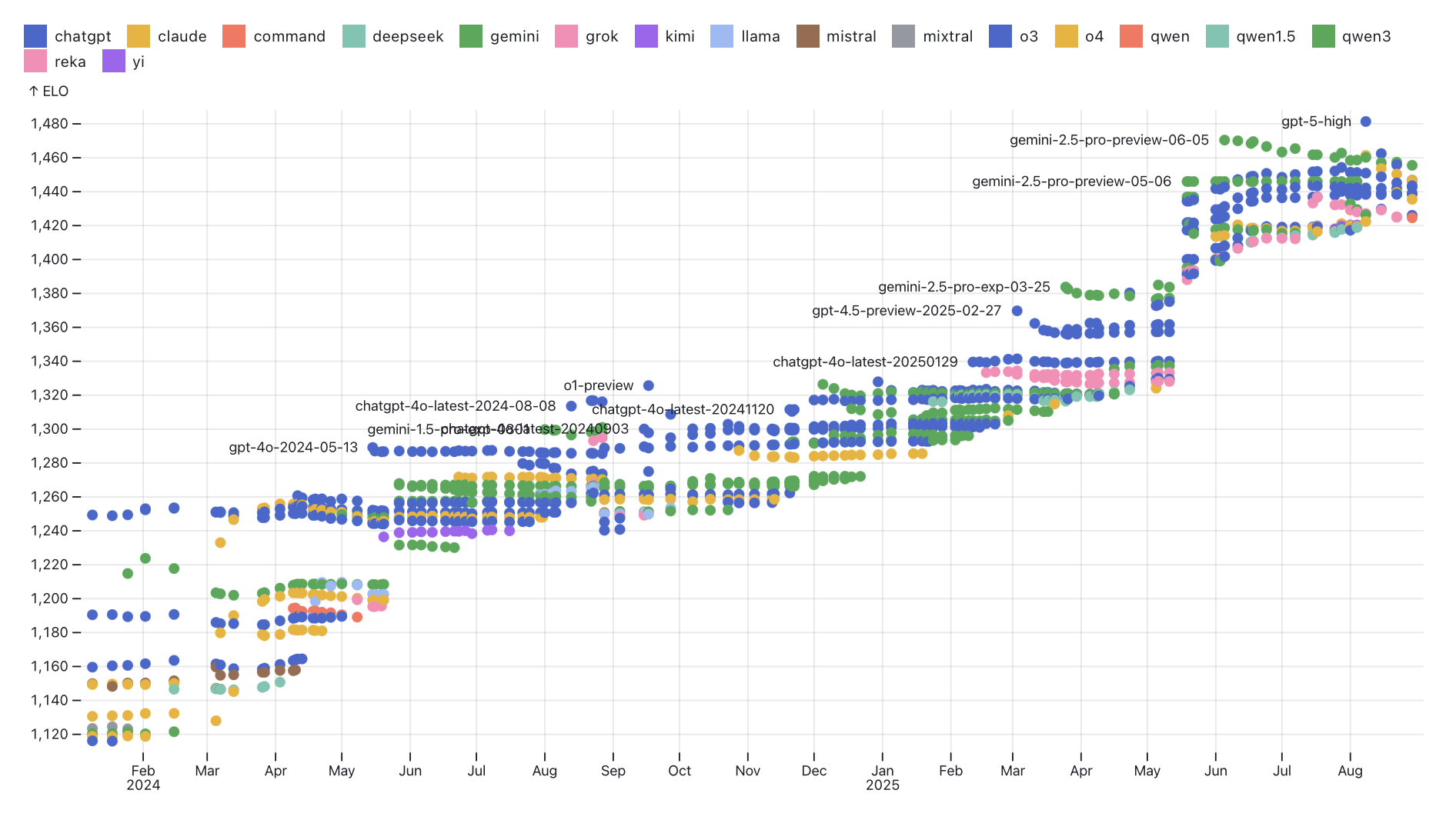 From ObservableHQ.
From ObservableHQ.
- The AI pessimism has mostly evaporated.
-
Over summer 2024 many economists predicted that AI would have small economic impacts:
- Daron Acemoglu predicted AI would add 0.06% to annual productivity growth over the next 10 years.
- Josh Gans said “I don’t think it will boost growth appreciably” over the next 10 years.
- Robert Gordon predicted small effects.
- Paul Romer predicted small effects.
I have heard much less of this kind of talk in 2025.
- GDP forecasts have been modeling diffusion, but ignoring capability growth.
-
Two quantitative forecasts of AI’s GDP impact are Acemoglu (2024) (0.06%/year) and Aghion and Bunel (2024) (1%/year). Both of those papers model AI’s future economic impact as primarily a diffusion process: they treat the arrival of AI as a one-time shock like electricity or the steam engine which is gradually adopted and adapted, but asymptotes.
I think this a bad assumption because AI’s capabilities have been getting dramatically better over time (discussed more above), and we don’t know where the ceiling is.
Conceptually, we can decompose the growth in LLM adoption over a given period into (i) quality growth; (ii) diffusion. It’s very difficult to separate these, but I think a reasonable guess is that growth over the last 12 months (Sept 2024 to Sept 2025) is about 1/2 diffusion of existing capabilities, and 1/2 the causal effect of new capabilities (precisely: growth would’ve been half as large if models had been frozen in Sept 2024). If this is true then a forecast which was just based on the diffusion of existing capabilities would have dramatically under-estimated the impact of AI, and the gap would become larger as the horizon got longer.
Forecasts of diffusion are, by construction, forecasts which assume that AI progress will stop. But neither of these papers gives an argument why we should expect that.
- GDP will miss a lot.
-
There are two reasons why focussing just on GDP will miss important effects:
AI will change relative prices. It seems likely that AI will lower the price of services (especially digital services) much more than the price of goods. If we just talk about the effect of AI on output overall, without distinguishing across domains, I think we will miss a lot. (I talk more about resource prices below).
AI services won’t show up in GDP. AI is already providing a great deal of value (there are 700M ChatGPT users), but the value mostly won’t show up in GDP by our normal accounting methods.3. In fact it’s plausible that AI reduces GDP because it reduces demand for expertise: I no longer call my garage-door-repair guy, because ChatGPT tells me how to fix the door. Services are generally accounted for in GDP just by the wages paid to service-providers. If people substitute from human service-providers towards AI then measured GDP will fall even though true output has increased. If service-providing firms pass through their cost-savings to customers then their measured contribution to GDP will fall. The same argument applies to much older technologies – the printing press, the encylopedia, YouTube.4
We don’t have a standard model of AI
- AI will change everything, but we don’t know how.
-
We want to predict the effect of AI on dozens of different areas of life – on medicine, on law, on entertainment, on news, on competition and markups, on scientific discovery, on personal relationships.
I will complain a little about the state of theorizing about the economic effects of AI. I feel that there’s not enough ambitious work which tries to model the effects of AI on human society in a deep structural way, which would allow us to make predictions across many domains.
If I’m missing some attempts please tell me.
- Each paper used a different assumption about AI.
-
Each of the papers in the NBER workshop used some assumption about how AI changes the production function, but there were many different assumptions. Some of the ways that AI is modelled:
- AI allows capital to perform a wider set of tasks (tasks that previously only labor could do).
- AI allows humans to do certain tasks more quickly.
- AI allows humans to do a wider range of tasks.
In many papers there’s no specific assumption on the types of task, just a parameter that reflects the share of tasks affected or the size of the effect. In some papers there are more structural assumptions on how tasks are affected, but there are a wide variety of assumptions, e.g. whether AI gives better predictions, or AI shares information. In some papers there are empirical assumptions, e.g. using an index of “AI exposure”.
Brynjolfsson, Korinek, and Agrawal (2025) is a “research agenda for the economics of transformative AI”: it seems to me that the paper lists many good questions but cites relatively few papers, and the papers it does cite are generally treated only as exploratory conjectures.
- Structural models of AI.
-
Here are two classes of somewhat more structural models.
Agrawal, Gans, and Goldfarb (2019) – here AI improves the ability to predict some outcome, & the authors argue these predictions are typically a complement to human judgments. A couple of notable features: (1) in this model AI and human intelligence are qualitatively different, they assume that only humans can exercise judgment, which I find hard to interpret; (2) the model doesn’t seem to naturally predict the knowledge-sharing feature that I would regard as the primary economic effect of LLMs (see below).
Ide and Talamas (2024) – here each human has a certain level of knowledge (on a single dimension), and AI is able to substitute for that knowledge. This is an application of Garicano and Rossi-Hansberg (2006)’s model of the effect of information technology on organizational structure.
- A pocket model: LLMs share knowledge.
-
Here is a simple mental model that I often use: LLMs share knowledge. The model is unsatisfactory in many respects but has the virtues of being very simple and very general. Consider an LLM as just a database of answers to questions, containing the set of answers that already exist in the public domain (i.e., in the LLM’s training set).5 LLMs therefore lower the cost of access to existing knowledge, and people will consult an LLM when they encounter a problem for which (i) they do not know the answer, but (ii) they expect that someone else does know the answer (and the answer was included in the training set).
This is a very crude model of an LLM but I think it gives a reasonable characterization of their adoption and effect so far. Around 1/3 of adults in rich countries are regularly using chatbots, and I think it’s fair to say the majority of the use is solving problems outside the domain of the user’s own expertise, but inside someone else’s expertise (see our ChatGPT paper). This knowledge-sharing model predicts that LLMs will flatten comparative advantage, so we should see more home production (people solve their own problems), less trade, and lower returns to experience.
The model has a number of imperfections as a general model of AI: (1) LLMs are often used to do tasks that don’t require knowledge outside the user’s domain, e.g. solving a problem that requires time and patience but not knowledge such as certain types of computer programming, writing, or creating images; (2) the model treats LLMs as strictly bound by the limits of human knowledge, this was a good approximation for early LLMs but it’s clear that AI is progressively expanding the boundary of human knowledge in a variety of ways.
This model is related to the Garicano-Ide-Talamas models in which an AI shares existing knowledge.
- Can we use existing models of human cognition?
-
There has been a lot of work by economists on the limits of human cognition over the last 50 years (AKA behavioral economics). This would seem like a natural quarry where we can get material for a theory of AI’s economic impact, however I’m not optimistic that there is much we can use.
Ideally we could start with a model of human decision-making and change the parameters to fit a model of computer decision-making. However there are not many clear candidates, theories in behavioral or psychological economics tend to emphasize biases: prospect theory, hyperbolic discounting, ambiguity aversion, heuristics, social preferences, rational inattention, two systems.
These are primarily theories of the weaknesses of human judgment, as such they do not seem to offer much explanation of the extraordinary strengths of human judgment – illustrated by the decades that it’s taken for computers to catch up with humans. These models don’t help explain why it has been so difficult to build a computer to do very basic human judgment and decision-making.6
A Conjecture About Deep Models
- AI’s effect on a domain will depend on that domain’s statistical structure.
-
This will be a somewhat vague statement: my guess is that the most satisfying explanations of AI’s impact across different domains of human life (entertainment, news, hiring, shopping, etc.) will refer to the statistical properties of those domains, such as the latent dimensionality of that domain, or the strength of correlations in that domain.
Put another way: are there aspects of the statistical structure of the domain which a human brain can comprehend, but a computer brain cannot? are there aspects which a computer brain can appreciate but a human brain cannot? We already have well-established statistical theory on which types of estimator perform better on which types of data-generating process, the conjecture is that this type of theory will help organize a lot of observations about the impact of LLMs on social processes.
This line of thinking is inspired by some standard theory underlying the success of deep learning: that neural nets are able to learn low-dimensional structures in high-dimensional data (the “manifold hypothesis”, Bengio, Courville, and Vincent (2013)).
- Examples of economic implications from statistical structure.
-
Here are a few brief cases in which the equilibrium economic effect of AI is determined by the underlying statistical structure of the domain. My conjecture is that these types of observations could be formalized in a common framework.
- The concentration of the market for AI depends on the dimensionality of the world. If the world is intrinsically high-dimensional then the returns to model scale will be steadily increasing, and so we should expect high concentration and high markups. If instead the world is intrinsically low-dimensional then the returns to scale will flatten, and there should be low concentration (high competition) and low markups.
- The effect of AI on scientific progress depends on the structure of the world. I give this argument below: if the world has a simple latent structure then progress will be bottlenecked more by intelligence than by data, and so advances in AI will dramatically accelerate scientific progress, without being bottlenecked on more data collection.
- The wages paid to an occupation depends on the work’s latent dimensionality. If the work consists of tasks with high latent dimensionality then the returns to experience and ability will be high, and so wages will be high. As AI changes the incremental effect of human experience and intelligence we should expect it to change the structure of wages.
- The demand for compute will depend on the self-similarity of the world. If 7 billion people all have very different problems then there are few efficiencies we can make in inference (through caching and distillation) and the share of GDP paid to compute will be high. If instead they have similar problems then the returns to additional compute will fall rapidly (demand will be inelastic) and the share of income paid to compute will be small.
- The value of a matching algorithm depends on the dimensionality of preferences. Suppose we are predicting the quality of a match between a person and an item (e.g. a viewer and a movie, or a person and a job). If the latent structure of match-qualities is very simple then classic collaborative filtering algorithms will be very efficient, and neural nets will have small additional value (e.g. suppose preferences over movies can be largely expressed on a single latent dimension). But if preferences are highly idiosyncratic then more advanced AI, and wider data sources, will have big effects on equilibrium outcomes.
If AI can do everything then wages will fall.
- What will happen when computers can do everything?
-
A lot of the discussion at both workshops was about the hypothetical world where computers can do everything that humans can do. Suppose there will be zero intrinsic demand for human-provision, i.e. people would not pay a higher price or accept a lower quality if a service was provided by a human instead of a machine. What would happen to human employment and wages.
Many papers argue that in this case human wages will increase: Pascual Restrepo made this argument at the NBER workshop (Restrepo (2025)), see also Caselli and Manning (2019), Smith (2024), Trammell and Korinek (2023) and Korinek and Suh (2024).7
The argument follows the standard trade argument: if a farmer moves in next-door who can grow every vegetable more efficiently than you then it’s good news: you can just specailize in the vegetables you are relatively better at and trade with the neighbor at an advantage. (If capital is a complement to labor then robots might cause wages to decline in the short-run but they would recover in the long-run, see Caselli and Manning (2019)).
- If resources are scarce, wages will drop.
-
This reassuring conclusion depends on there being no other scarce inputs which humans and computers compete for. All of the papers above mention this qualification, they say that the conclusions might change if there are fixed factors, but they do not put emphasis on this point. However it seems to me that if we take seriously the hypothetical (that computers can do all work that humans can) then the resource constraints will very quickly bind.8
Humans have resource inputs - say 100 square feet and 2000 calories/day. If a computer can do every task at a lower resource cost than a human, and there are plentiful computers, then there would be no humans employed in equilibrium.9 Concretely, humans who do not own land would starve: the price of their labor, denominated in energy and land, would fall below subsistence level.
Among people who are still alive (because they own land, or from charity), would they work? Only if the incremental resource cost of working was below the resource cost of using a computer for that job.
An analogy: suppose we have a stock of A100 chips, then we start introducing more powerful H100 chips. Assume the H100 can do more tasks/hour across all tasks. As we acquire H100s we will keep using A100s for the jobs they are comparatively better for. But once we have sufficiently many H100s we will start to unplug the A100s to make room.
- A feudal world.
-
Here is a sketch of a world with transformative AI. Probably I’m missing important things but I find it helpful to be concrete. Make these assumptions:
- Every service and every good can be produced by a robot, with 1hr of robot labor exactly equivalent to 1hr of human labor.
- A human requires 100 square feet to live, but a robot requires 1 square foot. I will treat land as the only fixed resource, you can imagine this as also representing energy and scarce minerals.
- Suppose robots are sufficiently plentiful that they are rented at their resource cost, i.e. 1 square foot of land.
- Suppose half of all humans own land while the other half do not. I.e. for half of all humans their only asset is their labor.
- Suppose there is no intrinsic demand for human labor, people only care about the quality of the output, not who made it.
For people who own property you now have as many workers as square feet of land. You can effectively order anything you want from Amazon, or get any arbitrarily high-quality service (medical, massage, education, entertainment). Your primary constraints are space and time, not quality or quantity of goods and services.
However suppose you do not own land, and pay rent every month. In order to provide a service cheaper than your landlord’s robot your wage needs to be equivalent to 1 square foot of land, i.e. less than subsistence.
Taken literally this implies that people without assets will become dependent on charity. It seems plausible that the landowners would provide land to the land-poor, but still there would be no employment in this scenario.
- A model with labor and land.
-
For completeness, here’s a simple model. Let land and labor be gross complements, and let AI be a perfect substitute for labor, and suppose we have an arbitrarily large quantity of AI. Then the marginal product of labor falls to zero and the entirety of the output will be held by the land-owner. Human labor no longer has any value and workers must live off the charity of the land-owners.
Formally:
\[Y=(\ut{N}{land}^\rho+{(\ut{L}{labor}+\ut{C}{computers})}^{\rho})^{1/\rho}\]
as \(C\rightarrow\infty\) then the marginal product of labor goes to zero, and all income goes to land.
Notes:
- I assumed labor and land are gross complements (\(\varepsilon=\frac{1}{1-\rho}<1\)). If production was Cobb-Douglas then making labor free implies we would get infinite output from a finite amount of land. As long as there is some limit on total output then land and labor must be gross complements beyond some point.
- I assumed AI labor is free. We could instead assume AI has some resource cost. In that case the price of labor will be driven down to the input cost of AI labor. The input cost of AI labor could be defined in a few ways but they all appear to me low compared to exiting human wages: the land cost of a GPU is a few square inches, the energy cost is 400 watts.
- We could distinguish between two sectors: a sector that requires land (goods) and a sector that requires only labor (services). If we introduce AI as free labor then human wages will retain the same purchasing power for services but their purchasing power for goods will collapse. Concretely: if you try to exchange your labor for goods you will have nothing to offer because the land-holder already has unlimited labor. The model predicts that workers will be not benefit from AI-produced-goods because AI requires land inputs.
AI scientists will be unlike human scientists
- Will efficiency curves start dropping faster?
-
A good way of making the AI R&D question very concrete is to look at historical input-efficiency curves across a lot of different areas, and try to predict where they will go in the future. Should we expect them to start dropping faster? Which ones?
-
In fact I think these efficiency curves are a very good subject for making forecasts about: both as an output (expressing the practical impact of AI), and as an input (a way of expressing the capability of AI, to then make conditional forecasts with).
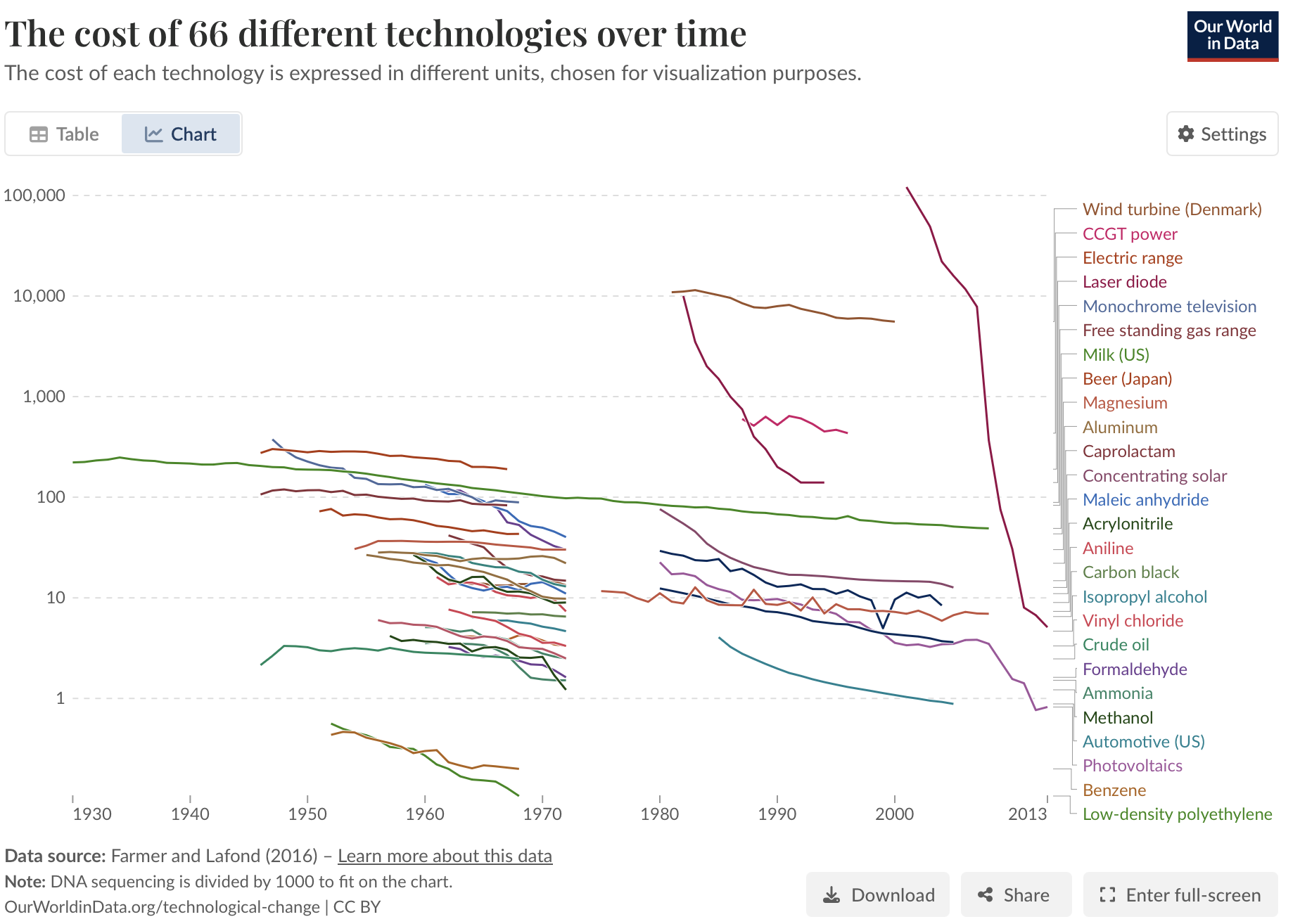
- Most models of AI R&D are based on human R&D.
- Models of AI’s impact on technological discovery are typically modelled on human R&D, e.g. (1) AI increases the effective supply of human scientists; or (2) AI automates one component of the R&D process. However both are modelled on a production function fitted on data with human researchers, and it seems to me likely that AI will qualitatively change that production function.
- There’s another way to model this.
-
My instinct is that there’s a different way of modeling this that is more structural. Suppose we have an unobserved landscape, and it can be explored either by a human brain or a computer brain. Human brains have been exploring the landscape, finding successively lower local minima, and also finding general patterns in the landscape (e.g. physical laws). We wish to understand how much computers will speed up exploration of the landscape.
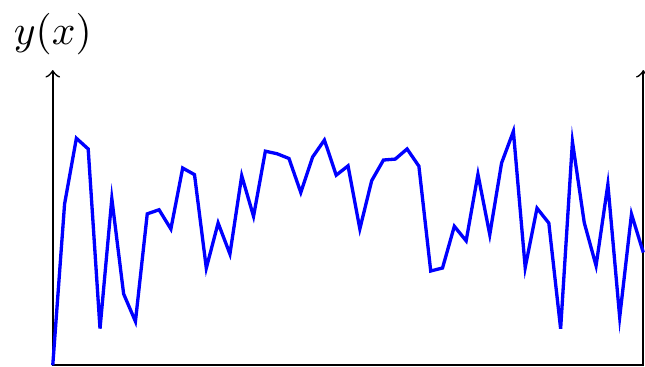
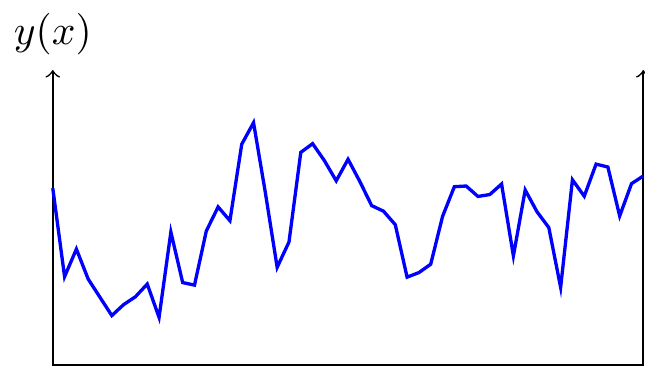
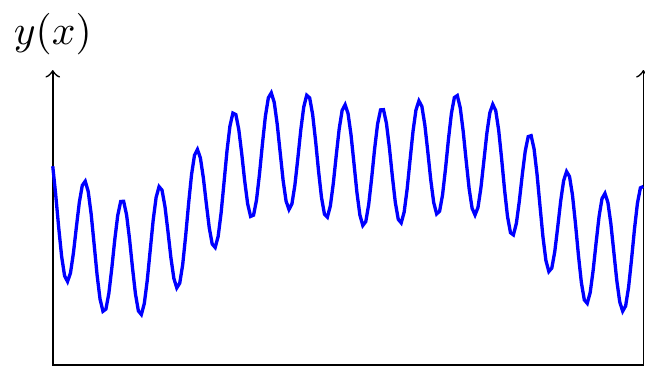
- The effect of AI depends on the type of landscape.
-
Represent the landscape with a function \(y(x)\), and each period we choose an \(x\) to minimize \(y(x)\). This is a well-defined explore-exploit problem, and we can characterize the expected progression of efficiency over time (the decline in \(y(.)\) over time) as a function of the statistical structure of the landscape:
- Random landscape: If each \(y(x)\) is completely independent there’s no intelligence needed in choosing \(x\) (beyond keeping track of which locations you’ve already tried). This is just drawing balls from an urn. The growth in efficiency as a function of \(N\) draws depends on the distribution of values of \(y\) (Muth (1986), Kortum (1997)).
- Rugged landscape: If \(y(x)\) is correlated across \(x\) but the correlation is local (e.g. if \(y(x)\) is a Weiner process) then the best-estimate of \(y(x)\) for a new \(x\) will depend only on the neighboring values of \(x\). Callander (2011) and Carnehl and Schneider (2025) characterize the optimal strategy. Again we are not constrained on intelligence, only on data: the extrapolation algorithm is fairly simple.
- Regular landscape: Finally suppose the landscape has some deep latent structure. In this case the best-estimate of \(y(x)\) will depend on the entire collection of previously-observed pairs \((x,y)\), and so we do expect that predictions could be improved with more intelligence, and so AI should have a big impact.10
- Implications of landscape regularity.
-
If the world has a regular landscape then we are not primarily constrained on facts, we are constrained on intelligence. Thus if we build a sufficiently powerful pattern-matching machine our progress might accelerate rapidly, without any new data collection.
-
Good examples of random landscapes are when we are mapping out specific features of the world. If we are making a list of specific objects (planets) or species (viruses), then the observations cannot be well-predicted from first principles, and we inevitably need new observations. Similarly, if we are mapping a genome then the exact sequence of base pairs requires individual observations, it cannot be accurately predicted from already-available data.
-
A good example of regular landscape is folding proteins: here we are learning a function from a sequence of base-pairs to a 3D shape. The function is high-dimensional but we have reason to expect a low-dimensional representation which would make it tractable - and AlphaFold found one.
- AI R&D has already lead to discontinuities.
-
Many fields which have been progressing slowly show a discrete change in the rate of progress when computers took over:
- Progress in solving optimization problems.
- Progress in proving combinatorics theorems (four-color theorem in 1976)
- Progress in chess strategy (Elo has fallen quicker since 1997)
- Progress in protein folding.
Some of these have hit provably global minima: the four-color them; sphere packing; Ramsey numbers; Nash equilibrium of checkers, connect 4, texas hold-em, and chess endgames.
These accelerations have occurred when computer intelligence has surpassed human intelligence for a particular type of pattern-matching. As computer intelligence becomes more general then we should expect more and more lines of progress to start accelerating.
- Aristotle already had the jigsaw pieces.
-
There’s a nice analogy for this: suppose we resurrected Aristotle, is it enough to show him our theories, or do we also need to show him the data we’ve gathered? Was he constrained on facts or intelligence? Did he already have enough jigsaw pieces, he was just lacking the insight?
-
It seems to me plausible that we could persuade Aristotle of some of the following from noting connections among the facts he was already aware of: that the sun is a star, that the earth goes around it, that the whale is not a fish, that the human is a monkey, that force is mass times acceleration, that temperature is motion, that pitch is frequency.
- Predicting the effect of AI on R&D is intrinsically difficult.
-
The landscape model I described above implies that we should expect AI to have a big effect when some domain has a latent undiscovered structure. But in many cases this is very difficult to know in advance: we don’t know where the floor is. It seems conceivable that there are some very simple undiscovered principles explaining cancer, fluid motion, evolution. But maybe these domains are irreducibly complex.
References
Citation
@online{cunningham2025,
author = {Cunningham, Tom},
title = {Economics and {Transformative} {AI}},
date = {2025-10-02},
url = {https://tecunningham.github.io/posts/2025-09-19-transformative-AI-notes.html},
langid = {en}
}